The work would not have been possible without the generosity of our funding partners: Georgia Public Library Service, BC Libraries Cooperative, South Carolina Library Evergreen Network, Bibliomation, and Central/Western Massachusetts Automated Resource Sharing.
Abstract
In February of 2013, Brad LaJeunesse, the president of Equinox Software, broached the idea of a community funded QA project
[http://georgialibraries.markmail.org/thread/i3x7nsd3eygau4nb]
to improve the state of Quality Assurance/Control/Management in Evergreen. It’s a broad topic, but a large part of what we meant, and what most people took it to mean, is better automated software testing. However, like security, QA is ultimately a process, and no amount of automated testing will create better software without adoption by the actual people who create the software. This report, and associated git commits, are the result of several months worth of work on the process; the fruits of which we hope will be adopted by others in the community.
[http://blog.esilibrary.com/2013/06/19/quality-assurance/]
Evergreen has always had QA processes,
[http://evergreen-ils.org/dokuwiki/doku.php?id=contributing]
which have become more rigorous as the software and community matured. Currently, changes to the software by one developer require a "sign-off" by at least one other developer, and all the developers involved "test" the changes before they land in the master version of the software. Release managers have the power to include/exclude any given feature or bug fix in the version-branch of the software they maintain.
These changes are documented in five places: 1) the version control system,
[http://git.evergreen-ils.org/]
2) the release notes and technical reference documents (in the docs/
[http://git.evergreen-ils.org/?p=Evergreen.git;a=tree;f=docs;hb=HEAD]
subdirectory), 3) the bug/feature database,
[http://bugs.launchpad.net/evergreen/]
4) within the code itself via inline comments, and ultimately 5) through the end-user documentation.
[http://docs.evergreen-ils.org/]
Occasionally and sporadically, the developers will create automated "unit" tests and/or describe manual test cases for the changes.
For the unit tests, and for the overall process of compiling/building Evergreen, we have a tool called Buildbot
[http://testing.evergreen-ils.org/buildbot/]
that will automatically build and test Evergreen after a set of changes have been committed to the master version of the software. Buildbot alerts all developers of any build failures or, in other words, whenever the build has become "broken".
There is a very good reason why unit tests are not more widely used by Evergreen developers. Evergreen was not designed in such a way that makes it easy to test behavior at the unit level. The "state" of Evergreen as a machine is spread across multiple mechanisms such as the database, the memcached service, configuration files, and memory allocated to specific processes. Actions within Evergreen can have "side-effects" that affect other actions, and sometimes communication between processes have to be "pinned" to each other and not shared with their peers. There’s no generic way to create a mock environment with a limited scope for actions to affect at the micro-level.
Due to the above issues, the main tack this project ended up taking was to create mock environments on a larger scale and test Evergreen with its whole stack running. I’ve referred to these sort of tests as "live tests", but they can also be called integration tests, dynamic tests, feature tests, etc. They assume that they will be applied against a running instance of Evergreen. While not yet integrated into Buildbot, we do have a summary page and RSS feed for the results of these tests
[http://testing.evergreen-ils.org/~live/test.html]
. The hope is that the comparative ease with which these tests can be constructed over unit tests combined with a nightly automated run of such tests will spur the creation of more such tests, and that Evergreen will benefit from this.
The Bullet Points
The project had deliverables:
-
Identify and assess the efficacy of existing resources and processes.
-
Deploy examples of unit tests for each language and domain within Evergreen.
-
Deploy examples of API tests for Evergreen’s internal and published APIs.
-
Demonstrate through initial implementation how continuous integration can provide regression testing.
-
Document, with narrative, an example usability test and analysis, and the resolutions to problems discovered.
-
Identify or create best examples of developer documentation for each language and domain within Evergreen.
-
Analyses of available UI testing automation tools, and, if possible, design of a UI Testing framework.
Identify and assess the efficacy of existing resources and processes
In 2011 the Evergreen community adopted git
[http://gitscm.com/]
for decentralized version control,
[http://en.wikipedia.org/wiki/Distributed_revision_control]
[http://evergreen-ils.org/dokuwiki/doku.php?id=dev:meetings:2011-04-30]
allowing interested developers to more easily develop functionality in isolation from each other while retaining all the benefits of a common version control system. Soon after, we began to mimic the Koha community with the requirement for developers to "sign-off"
[http://wiki.koha-community.org/wiki/Sign_off_on_patches]
[http://evergreen-ils.org/dokuwiki/doku.php?id=contributing#submitting_code_to_the_project]
on each other’s work before allowing a change to be committed to the "master" version branch of Evergreen. Change requests would be documented in Launchpad and tagged with "pullrequest".
[http://evergreen-ils.org/dokuwiki/doku.php?id=dev:meetings:2011-05-24]
Any change committed to the common master branch is now vetted in order to improve code quality and, though we don’t have easily accessible metrics on effectiveness, the overall consensus is that code quality did improve. For larger changes, a developer or release manager will even ask for more than one sign-off in order to get more eyes on the code. Our main problem at this point is that the developers tend to have a backlog of pullrequest branches, so known problems may be fixed, but not in released versions of Evergreen.
Another policy that helps code quality is the use of specific upgrade scripts for any changes that affect the database, and how developers will call dibs on the next number in a sequence to associate with the upgrade script and use for populating the config.upgrade_log table. This effectively serializes a part of our normally concurrent development process and helps us to avoid code conflicts when we merge changes into master. However, there is room for improvement with how we use upgrade scripts, particularly with how we combine them into larger upgrade scripts for going across released versions. There is functionality stubbed out that the community hasn’t yet implemented for deprecating and superseding scripts.
2011 also brought us use of Buildbot,
[http://buildbot.net/]
which supplanted an earlier effort under the same name. Buildbot is a continuous integration
[http://en.wikipedia.org/wiki/Continuous_integration]
framework which currently builds Evergreen and runs its unit tests whenever code changes are made to the master branch of Evergreen. Buildbot does this in a distributed manner across multiple "drones" running on different servers with different operating systems, giving us some cross-platform testing. Since developers tend to test their work in a limited number of environments, it is extremely beneficial to have automated cross-platform testing, particularly when it comes to catching missing dependencies. Buildbot can potentially do much more, such as build release packages of Evergreen and run the integration tests developed as part of this project, as well as test code branches other than master. Buildbot alerts developers to problems via messages in the #evergreen
[http://evergreen-ils.org/irc.php]
IRC channel, where most of the developers congregate to have real-time discussion. The main problem with Buildbot is that the developers are not developing a whole lot of tests for it.

Before Buildbot, automated tests for Evergreen could be found in a project called Constrictor
[http://git.evergreen-ils.org/?p=working/random.git;a=tree;h=refs/heads/collab/berick/constrictor;hb=refs/heads/collab/berick/constrictor]
, which is mostly geared toward stress testing. It too uses drone servers, but as a way of distributing the firing off of tests to a single specific target instance of Evergreen. The issue with Constrictor is that its website and documentation has disappeared with the community’s move from Subversion and TRAC to git, gitweb, and Lauchpad.
Another move toward better testing was the creation of optional stock test data for optionally loading into an Evergreen instance. Scripts were created in 2008 for generating random data
[http://evergreen-ils.org/dokuwiki/doku.php?id=advocacy:demonstration_data]
and sample bib records
[http://git.evergreen-ils.org/?p=working/Evergreen.git;a=tree;f=Open-ILS/tests/datasets;hb=HEAD]
were added. Eventually, other stock data such as users, transactions, etc. were added, which proved better than random data for reproducible testing; however, there is plenty of room for improvement. For example, we don’t have any stock bills for our test patrons nor do we have items in transit, so the data is far from a snapshot of a live production system. One complication that can affect testing is the notion of time. For example, many of the due dates in the sample circulations have already been hit, so the number of overdue items alone changes depending on when the test data is loaded. It may be worth setting test servers to a fixed date in the past going forward, or rig the data such that all dates are relative to the load date.
Finally, we have manual and exploratory testing by stakeholders other than the developers where some libraries will test upgrades and new versions of Evergreen in a non-production environment prior to allowing these changes onto their production systems. This is an important process for Evergreen, and bugs discovered this way are often communicated to the developers. One way we could improve this process is by cleaning up the noise in the log files produced by Evergreen. It’s common to see "errors" in the logs that routinely get ignored because they have little or no noticeable effect on end-users, but these errors can obscure real problems. Moreover, sometimes the errors aren’t harmless after all but the error goes unreported or, if reported, they’re difficult to later link to the errors in the logs.
Currently, there is the most to gain from the sign-offs between developers and testers, which includes manual and exploratory testing by the parties involved. In practice, Evergreen developers rarely break a build outright, and more subtle bugs are not caught by the build process or the tests run by Buildbot today.
Deploy examples of unit tests for each language and domain within Evergreen
Unit tests
[http://en.wikipedia.org/wiki/Unit_test]
have a lot of mindshare in the testing world. For unit tests you essentially rig tests for small well-contained bits of code, such as functions, modules, or classes, and hopefully, they can be ran independently of each other. If you can write tests before you write the code they exercise, then you’re essentially doing test-driven development
[http://en.wikipedia.org/wiki/Test-driven_development]
and getting pretty close to design by contract,
[http://en.wikipedia.org/wiki/Design_by_contract]
both of which have a lot of adherents. Unfortunately, Evergreen wasn’t designed with unit testing in mind, and we have a lot of business logic that is not tightly contained. Before this project, we had a few unit tests implemented in C for OpenSRF
[http://git.evergreen-ils.org/?p=working/OpenSRF.git;a=summary]
, a main component of Evergreen, and within Evergreen itself, a few unit tests implemented in Perl.
As part of this project, we added an example unit test in Perl
[https://bugs.launchpad.net/evergreen/+bug/1190717]
and cleaned up an existing test. We also ported the C unit test harness from OpenSRF to Evergreen and added some examples
[https://bugs.launchpad.net/evergreen/+bug/1194643]
in that language as well. Unit tests for GUIs are notoriously difficult, so we deferred doing this with Javascript and Template Toolkit, preferring to wait for the part of the project dealing with UI testing. We also didn’t create any unit tests in Java, Ruby, or Python. Technically, we do have files in the Evergreen source tree written in those languages, but they’re not widely used throughout the Evergreen backend like Perl and C. XSLT was also omitted.
I feel that the biggest win with unit tests will come from pgTAP,
[http://pgtap.org/]
with which we have created a few example unit tests
[https://bugs.launchpad.net/evergreen/+bug/1194246]
to supplement ones that had already been created as a proof of concept. We also created a script to generate a base set of pgTAP tests
[https://bugs.launchpad.net/evergreen/+bug/1205464]
for validating the entire database schema. The idea here is that if we can get a commitment from the core developers, we can use this script once to create a base set of tests that we can then commit to the master branch. From then on we can simply maintain and modify those tests whenever we create a database upgrade script. These tests can then prove that both the upgrade scripts and the seed files do the same thing, and folks performing upgrades can sanity-check their work to ensure that they didn’t miss invoking an upgrade script, or that an upgrade script somehow failed unnoticed.
To summarize, Evergreen developers are not making effective use of unit tests today, but this is because it is very difficult to do so given Evergreen’s nature. Using pgTAP in the database seems the most likely path for success here, but even with it you may have to put extra effort into developing mock environments for each test. We recommend that the community focus on integration tests that rely on pristine loads of test data in running systems.
Deploy examples of API tests for Evergreen’s internal and published APIs
Technically, Evergreen has multiple kinds of APIs and ways of invoking them, but our intention was to focus on the API methods registered with OpenSRF.
[https://bugs.launchpad.net/evergreen/+bug/1206531]
Given Evergreen’s nature, we did these as integration tests instead of unit tests, and rely on a script
[http://git.evergreen-ils.org/?p=working/random.git;a=blob;f=installer/wheezy/eg_wheezy_installer.sh;hb=refs/heads/collab/phasefx/wheezy_installer]
that installs, configures, and runs Evergreen, and then runs our integration tests against that live test instance. Given the long term difficulty of creating tests where the side-effects can be perfectly reversed for repeat runs, the idea here is that the server running the test instance will be restored to a pristine condition prior to each test run, eliminating risk of contamination from previous runs. However, future work should be geared to create tests that clean-up after themselves as much as possible, for easier testing of the tests themselves when building them. There was slight deviation from this with the bills created in 03-overdue_circ.t and 04-overdue_with_closed_dates.t, delaying their cleanup until 05-pay_bills.t. Since these aren’t unit tests, it is okay for preceding tests to build up conditions for subsequent tests to expect and exploit but, overall, I think the tests should clean up after themselves as much as they can once they’ve all been run. In the Koha community, their database dependent tests tend to be ran inside of transactions that can be rolled back, and we may want to adopt that strategy.
Integration testing is the way forward for Evergreen. It removes the burden of designing mock environments from the test creator, but does rely on the tested Evergreen instance being in a known/pristine state with stock test data. Tests should try to clean up after themselves to help mitigate changes to the shared environment during concurrent development, but to lower the barrier for development it shouldn’t be a hard requirement. This strategy also doesn’t preclude the creation of test data by the tests themselves.
Demonstrate through initial implementation how continuous integration can provide regression testing
Regression testing
[http://en.wikipedia.org/wiki/Regression_testing]
originally referred to the practice of coding tests for known bugs that had been fixed. This process ensures that the fixes were not fragile and don’t negatively impact other areas of code, but these days it is more encompassing and can be used to help find new bugs as well. Regression testing can include both unit tests and integration tests.
For our integration tests, an external server (analogous to a Buildbot master) is responsible for kicking off the test run on a test server (analogous to a Buildbot slave) using an additional script,
[http://git.evergreen-ils.org/?p=working/random.git;a=blob;f=installer/wheezy/installer_installer.sh;hb=refs/heads/collab/phasefx/wheezy_installer]
and collecting and parsing the results using a third script.
[http://git.evergreen-ils.org/?p=working/random.git;a=blob;f=qa/test_output_webifier.pl;hb=refs/heads/collab/phasefx/wheezy_installer]
The output from this process lives on a web page
[http://testing.evergreen-ils.org/~live/test.html]
and is published through an RSS feed
[http://testing.evergreen-ils.org/\~live/test_rss.xml]
that a "bot" on the #evergreen IRC channel may subscribe to. However, in the long run we will likely want to integrate this process with Buildbot so that we can more easily handle multiple test servers and the archival of output from past runs. We’ll eventually want more complicated test environments such as multi-server Evergreen clusters using database replication, with optional intentional replication lag, to better exercise all parts of Evergreen.

This is a minimal implementation that is functional but could be expanded. For example, the scripts could expose data from previous runs and make comparisons with the data. It could tie in Constrictor and publish results from that testing. The community could impliment this in Buildbot to better support the handling of multiple test instances.
Document, with narrative, an example usability test and analysis, and the resolutions to problems discovered
In February of 2013, a self-hosted customer approached us with reports that their circulation system was performing slowly. Several different tacks were taken, including:
-
the collection of reference timings from a local test system
-
the collection of reference timings from the production system with a local client
-
the collection of reference timings from the production system with a production client via a remote desktop connection
-
an attempt to determine whether the performance was being impacted by network conditions (packet loss, latency, VPN, transparent proxies, improper load balancing, etc.), by local application/environmental reasons (such as memory leaks forcing churn with virtual memory or 3rd party programs increasing local load), and/or server application/environmental reasons (such as runaway Apache processes, dead listeners, heavy load, etc.)
-
log data was analyzed with an eye toward timing and documenting redundant API calls
Aside from these technical tasks, there are some people/communication factors worth noting:
-
Based on previous experience, local staff may be skeptical/sensitive to suggestions that local factors may be at fault. Be clear when you’re just ruling out variables and not assuming fault.
-
Detail-oriented people (such as software developers) can sometimes miss the big picture. In this case, some time was spent focusing on the actual scanning of item barcodes through the checkout process, which could produce response times below a second per scan. In actuality, the pain points included the loading of the entire interface as well as incidental interfaces like the patron editor, which, from a staff perspective, are all part of the circulation experience. When reporting problems, it is common to lump different but similar problems together. Get direct reports from front line staff when possible—beware the telephone game.
Typical timings against the production system with a local client looked like this:
-
Login to workstation registration textbox - 15 seconds
-
Login to portal page - 30 seconds
-
Check-In interface loaded - 3-4 seconds
-
10 items scanned through Check-In - 20 seconds
-
Retrieve Patron textbox scan to Patron/Check-Out Display - 13 seconds
-
10 items scanned through Check-Out - 14 seconds
-
Patron Editor loaded - 18 seconds
However, staff clients in advanced stages of memory consumption from memory leakages were severely degraded when it came to such actions. Subsequently, work was done to address as many memory leaks as possible.
[https://bugs.launchpad.net/evergreen/+bug/1086458]
A smaller tweak to disable Barcode Completion look-ups was also made.
[https://bugs.launchpad.net/evergreen/+bug/1128303]
Past experience showed that tunneling staff client traffic (which is already SSL encrypted) through a VPN would impact performance but, in this case, site to site VPN was very fast and added negligible latency. The load balancer was also ruled out as a problem (in some cases we have seen pound out-perform ldirector). The Evergreen server was not under heavy load.
So, memory leaks were a big problem, but not the only problem. Going by the timing data listed above, it was taking half a minute to effectively get to the point where we could edit a patron’s account, and log analysis was showing this to be a design problem.
There were 13 client-side API calls, 5 of which were redundant. Given the complexity of the client code responsible for that, it seemed a simpler option to re-implement in as light-weight a manner as possible and go forward from there.
[https://bugs.launchpad.net/evergreen/+bug/1161122]
Now we only have 7 client-side API calls, only one of which was redundant. It is faster and has cut down on the number of restarts needed due to memory leakage, but I haven’t pushed for inclusion into master since it’s missing I18N, trades functionality (gains some, loses some), and the long-term plan for the staff client is up in the air. But this does illustrate how one might perform an analysis like this.
In general:
-
Check assumptions and language; make apple to apple comparisons as much as possible
-
Instrument the code, record metrics.
-
Change one variable at a time, record metrics. Process of elimination.
-
Explore alternatives, one variable at a time if possible.
Identify or create best examples of developer documentation for each language and domain within Evergreen
Good technical documentation makes collaborative development easier. Coming from the original author of a given section of code, or at least from one of her close associates, good technical documentation expresses ideas about the design and intent of a given section of code. Such expression allows others to check their assumptions about how the software should behave today and to temper their plans for changing the way it should work tomorrow. All of this can improve software quality.
In-line documentation
A great deal of technical documentation is written directly alongside the code that it describes. Strong examples for each major language used in Evergreen can be found below. The selected examples make clear to other programmers 1) how they should invoke the function being described and 2) what the function does, so that programmers who would add or change functionality have some notion of what behavior ought to be preserved.
Perl
See Serial/OPAC.pm
[http://git.evergreen-ils.org/?p=Evergreen.git;a=blob;f=Open-ILS/src/perlmods/lib/OpenILS/Application/Serial/OPAC.pm;h=6422edc248;hb=refs/heads/master#l71]
lines 71 through 222. These lines comprise a complex API method and its register_method() call, which includes API documentation.
The method itself contains a reasonable distribution of inline commentary. Although the Python language is not heavily used within Evergreen, the Python community has produced an excellent, concise set of guidelines for code commentary (PEP 8)
[http://www.python.org/dev/peps/pep-0008/]
which I will summarize and re-phrase here in order to apply it to Perl code in Evergreen.
-
Comments that contradict the code are worse than no comments.
-
Comments should be complete sentences with appropriate capitalization for ease of reading.
-
Follow a conservative style guide for writing in English, such as Strunk and White’s The Elements of Style.
-
Block comments generally apply to some or all of the code that follows them and should be indented to the same level as the code they describe.
-
Block comments are better than inline (short, sharing a line with the code) comments for all but very simple commentary.
-
The register_method() call for all API methods should include a well-formed signature argument whose value is a hash containing these keys and values:
-
desc: A string describing the purpose and general operation of the method
-
params: An array of hashes whose own keys are name, desc, type, and sometimes class (indicating a Fieldmapper class hint when type is “object”), describing each of the parameters, or arguments, to the method.
-
return: A hash whose own keys are desc, type, and sometimes class, whose meanings are the same as in the hashes inside the params array.
-
All but the last major bullet point in the above list could apply to code commentary in any project, but the one about register_method() is specific to applications built on OpenSRF, such as Evergreen services. The documentation of API methods in Evergreen, when correctly done, allows tools to produce online representations of the documentation automatically. They look like the following screenshot, and they can be accessed with relative ease through a web browser.
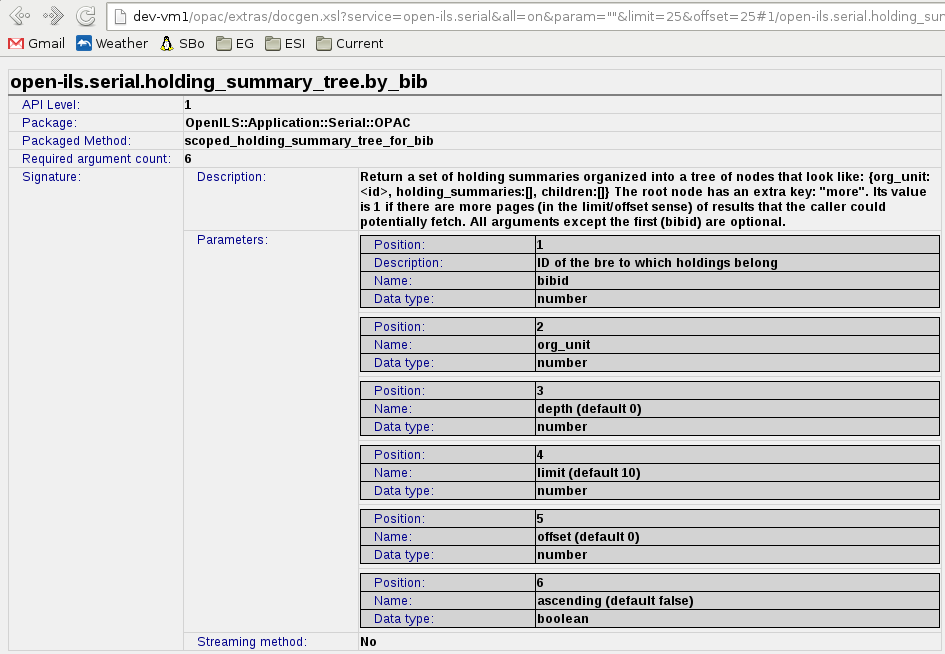
Javascript
See AutoSuggestStore.js
[http://git.evergreen-ils.org/?p=Evergreen.git;a=blob;f=Open-ILS/web/js/dojo/openils/AutoSuggestStore.js;h=d598159f0c05b42ea89f646a222575acf0501927;hb=refs/heads/master]
and consider the file as a whole.
Dojo is used to define a class which, strictly speaking, is not a concept represented in the Javascript language itself. Nonetheless, Evergreen makes liberal use of classes as well as other code and data structures offered by the Dojo toolkit.
Comments in this example explain the possible arguments to the constructor. Other comments denote which of the methods serve to embody a specified Dojo API, and others still explain the methods which serve the class’ own internal (or Evergreen’s) purposes.
SQL
See 020.schema.functions.sql
[http://git.evergreen-ils.org/?p=Evergreen.git;a=blob;f=Open-ILS/src/sql/Pg/020.schema.functions.sql;h=c0eb8af385c18ea15fceb8ad4b95e0e6228b83a3;hb=refs/heads/master#l272]
lines 272 through 294.
Note the separate CREATE FUNCTION and COMMENT ON FUNCTION statements.
In psql, the standard command-line interface to PostgreSQL databases, the \dt+ table command reveals comments.
SQL comments starting with “--” are also appropriate, and should especially be used to make the meaning of function arguments clear, although the rest of the points about commentary under the Perl heading of this document also apply.
C
See c-apps/oils_sql.c
[http://git.evergreen-ils.org/?p=Evergreen.git;a=blob;f=Open-ILS/src/c-apps/oils_sql.c;h=eb3f48b498e3d8eea2d22eccc18e337dc72591cb;hb=refs/heads/master#l2357]
lines 2357 through 2454.
The C programming language in particular, by virtue of its maturity and its ubiquity, has many supporting tools for extracting, formatting, and even automatically generating documentation. Much of Evergreen’s C source code is marked up with comments in a format meant to be processed by doxygen to produce documentation that looks like this:
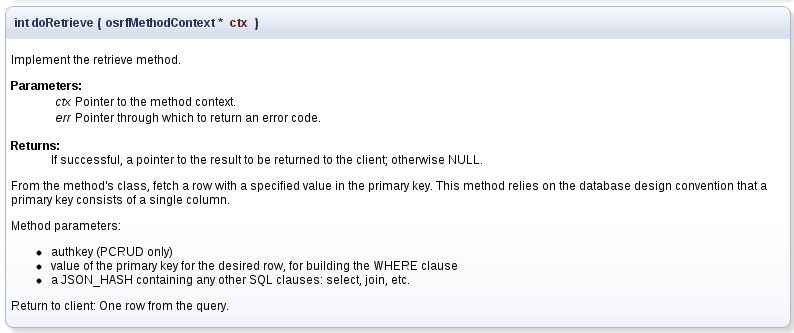
Sticking to a format that doxygen will understand for function overview documentation, as well as following the same general practices for block and inline comments as in other languages, is advisable.
Technical reference documentation
So far we have covered the sort of documentation that is commingled with code. There are also other important kinds of technical documentation for Evergreen. Recently, the Evergreen project has begun to incorporate more and better documentation in the form of technical reference, meant to convey ideas about design and function that are larger than what can be described in the context of a single API method or blocks of code in a given file.
In Evergreen, technical reference is placed in the docs/TechRef subdirectory in the source repository. Some early files are in the DocBook
[http://en.wikipedia.org/wiki/DocBook]
XML format, but newer contributions are in AsciiDoc
[http://www.methods.co.nz/asciidoc/]
, which is now favored by the community for project documentation (including end-user documentation).
Like DocBook, AsciiDoc can be edited with any text editor and serves as input to programs that produce refined representations in formats like PDF and HTML, sparing editors from the need to convert documents or maintain changes to different versions of a document. Unlike DocBook, AsciiDoc has a very simple syntax and is more approachable for non-technical writers.
The AsciiDoc here, TechRef/LinkChecker.txt,
[http://git.evergreen-ils.org/?p=Evergreen.git;a=blob;f=docs/TechRef/LinkChecker.txt;h=51b2c64de4c;hb=cdec380cf7]
can be used to produce HTML output formatted like so (example cropped):
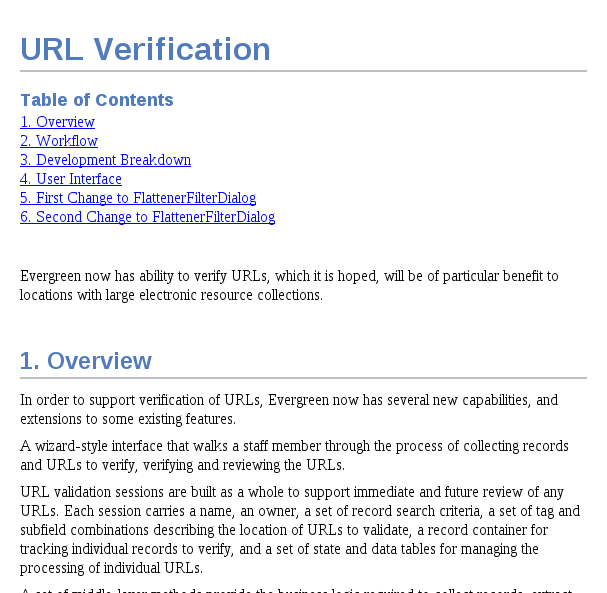
The QA report you’re reading now is also written in AsciiDoc.
Summary
Good communication is key to Evergreen development, and good documentation enshrines, formalizes, and preserves this communication. The most important areas include technical references (which can inform end-user documentation), API signatures, and developer-focused inline source documentation. It’s worth highlighting, maintaining, and improving these.
Analyses of available UI testing automation tools, and, if possible, design of a UI Testing framework
Challenges
These are some of the challenges with testing various user interfaces (and Evergreen’s in particular):
-
UI testing tools typically depend on the platform and/or the technology stack. Evergreen is cross-platform, and has both a web interface and a local client application that needs testing. The local client in particular uses different technology stacks (such as XUL and Dojo) for different interfaces.
-
UI testing tools not tied to specific languages and UI libraries typically use unique scripting languages not known by the developers, increasing the barrier to entry.
-
Some UI testing tools are intrustive and require changes to the code and introduction of testing hooks to the UI.
-
UI output is difficult to capture; screenshot analysis is hampered by such variables as fonts, skins, platform-specific UI conventions, placement, etc.
-
Tests are often brittle and can be "derailed" because of possible UI variations and unexpected dialogs, and the opaqueness of UI state to the testing tools.
-
Using either scripting or "Record and Capture" functionality can be laborious and error prone.
-
"Record and Capture" may not generate scripts that are amenable to good programming practices like abstraction, and at worse tests generated this way may need to be completely re-done when the UI changes
-
Automated test generation, which is desirable for good code coverage, is difficult and depends heavily on the technology stack.
-
Developers and other test writers will typically exercise limited code paths when navigating the UI and performing tasks, whereas users new to the software may meander and come up with novel paths that can expose bugs. Similarly, it is difficult to automate the random variations introduced by manual testing that may expose bugs, old and new
Snake Oil?
There’s some sentiment
[http://web.archive.org/web/20121031031802/http://blog.objectmentor.com/articles/2010/01/04/ui-test-automation-tools-are-snake-oil]
in the testing community that UI testing is typically a drain on resources and/or overpromised as a panacea by those who push UI testing solutions. The thought is that for UI testing to be done "right" the UI has to be designed for testing in mind, much like every other part of the software stack. In practice, this means having a strong separation of concerns; for example, using Model-View-Controller
[http://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller]
to avoid putting business logic into the UI, and testing the UI itself (that the controls function, etc.), but not functional testing of the app through the UI as if it were an API. Maybe we can design for testing as we move forward, but we don’t have it now with our current UI’s.
So do we still benefit from UI testing? I think so. Maybe functional testing of business logic is best done on the server if we can help it, but non-functional testing such as measuring performance and checking for memory leaks is important, as well as testing for regressions in the UI itself. For example, bug 1017989,
[https://bugs.launchpad.net/evergreen/+bug/1017989]
where the results of the Clear Shelf action were not rendered if there were 25 or more shelf expired holds being processed, was fixed as if it were a UI-level bug. A regression test could check that the fix was not brittle or impacted by other changes. I do agree that we don’t need to religiously duplicate tests that already exist elsewhere in Evergreen’s stack. So for example, there is a Perl test that covers closed dates and fine creation; we most likely wouldn’t benefit from reproducing this test in the staff client.
Specific Tools
Here are some specific tools that may work for us, the tactics they use, and how they try to overcome (or not) the challenges presented.
AutoHotKey
AutoHotKey
[http://www.autohotkey.com/]
is not specifically designed for UI testing, but for UI automation, though as a lower-level tool it can serve that purpose with a bit of extra work. I include it because we have used AutoHotKey in the past for stress testing the Evergreen staff client. At that time it was simply used to fire off a sequence of keystrokes over and over, and manual inspection was used to look for memory leaks, etc. More recently we used this same strategy to test for a specific memory leak, but had AutoHotKey use Irfanview
[http://www.irfanview.com/]
to take screenshots of Process Explorer
[http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx]
at regular intervals to record memory usage.
This notion of UI testing tools taking screenshots is very common, but as said before, it does present challenges, particularly if we want to automate the analysis of the images.
AutoHotKey has its own scripting language which is Turing complete, and there are methods for getting information such as state and text from certain UI controls like textboxes, as well as an image search function for comparing parts of the screen with previously saved images. Scripts can also wait for specific windows to become active before performing actions. All of this allows for conditional scripting that can be more reactive to events than a mere sequence of keyboard and mouse clicks.
What’s missing out of the box is a macro recorder for generating scripts automatically from user interaction and support for treating scripts as tests that can pass or fail and be grouped into suites. There are user-contributed scripts from the AutoHotKey community that try to fill some of these gaps. Though open source, AutoHotKey is tied to the Windows operating system and some of the control inspection functionality only works for specific Win32 UI controls which certain applications (such as Google Chrome
[http://www.google.com/chrome/]
) may not use.
Selenium
Selenium
[http://docs.seleniumhq.org/]
is a tool for automating browsers, primarily for the purpose of UI testing. There are two main parts to it: the Selenium IDE
[http://docs.seleniumhq.org/projects/ide/]
, which is a Firefox
[http://www.mozilla.org/en-US/firefox/new/]
add-on for recording, and Selenium WebDriver
[http://docs.seleniumhq.org/projects/webdriver/]
, a collection of language bindings that can drive many different browsers.
The IDE can record UI events such as a button clicks and use knowledge of the DOM
[http://en.wikipedia.org/wiki/Document_Object_Model]
to accurately represent these in spite of local rendering differences based on, for example, font and screen resolution. In addition to being able to record and playback user interaction within the browser, you are also able to make "assertions" about the content, such as the presence of specific text on a page. This allows you to turn a sequence of events into a test that can Pass or Fail, and you can group these tests into suites to run together.
This alone seems very promising for testing of the OPAC (and indirect testing of everything beneath it). Though the IDE itself only works with Firefox, it is able to export its tests to other programming languages that make use of the Selenium WebDriver libraries, which support other web browsers. These languages includes those common to Evergreen, and it makes these scripts easier to tweak and rewire to be more data-driven. However, these exported scripts cannot be re-imported back into the IDE.
There’s also support for distributed testing across many browsers at once.
Somewhat intriguing and a little frightening is the notion of integrating Selenium with XULRunner,
[https://developer.mozilla.org/en-US/docs/XULRunner]
the underlying platform for the Evergreen staff client, as XULRunner is built on the same Mozilla technology stack as Firefox. This was done as an experiment by others in the Mozilla community back in 2007
[http://praveenmatanam.wordpress.com/2007/12/27/convert-firefox-extension-to-xulrunner/]
, but it is not a supported use of Selenium. It would require changes to our code to come even close to working, as Selenium makes many assumptions about the environment in which it runs (Firefox). Since we are currently stuck on an obsolete version of XULRunner
[http://evergreen-ils.org/dokuwiki/doku.php?id=dev:meetings:future_of_staff_client]
, we would also have to use an obsolete version of Selenium. All of this makes the notion of attempting to use Selenium for the staff client less attractive than it might have been under different circumstances.
All in all, I think Selenium as a whole may be worth pursuing for testing our web interfaces, though not our XULRunner-based staff client.
Sikuli
I ran into errors trying to install Sikuli
[http://www.sikuli.org/]
in my test environment, but based on its documentation, it seems interesting. It has an IDE like Selenium, but works with any application like AutoHotKey. It’s implimented in Java and integrates with jUnit, so supports unit testing. The most obvious distinguishing feature is its emphasis on using screenshot snippets for identifying UI elements and state. With the IDE you can highlight a part of the screen by drawing a rectangle, for example, around a button. That image can then be treated as an identifier that you can use in expressions or pass into functions as parameters.
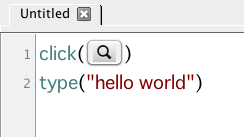
The main concern is that these tests may be very brittle based on variations in UI rendering depending on the environment. I couldn’t find any discussion for this, but if I were using this system I would abstract the use of image matching as much as possible, such that a given image would only appear once for an entire test suite, and be referred to by name/function everywhere else. I’d also be tempted to have a "trainer" page for the OPAC and one for the staff client, which would step through all UI controls, and perhaps allow a Sikuli test suite to dynamically populate these abstractions for buttons, etc. It could still be brittle. For example, with Selenium you could assert that a given line of text appears on the screen, but with Sikuli, you’d have to depend on its optical character recognition functionality to parse the text first. A mere screen image could not account for word wrapping.
It’s a very slick concept, but the UI testing options that take advantage of knowledge of UI internals are more attractive, particularly if we want to test with multiple locales.
LDTP
LDTP
[http://ldtp.freedesktop.org/wiki/]
looks very promising at it is cross-platform and cross-language, with bindings for languages that Evergreen developers are familiar with, such as Python and Perl, which also means we can use it in test suites for those languages. The way LDTP achieves cross-platform functionality is by relying on the same accessibility libraries that screen readers and other assistive technologies use. If an application doesn’t support accessibility, then you’ve found your first bug.
LDTP lets you generate mouse clicks and keypresses, but you can also manipulate controls more semantically. You can use pattern matching to refer to elements and configure callbacks for unexpected dialogs, and you can introspect your way through the object hierarchy presented by the accessibility libraries. Like Selenium, you can distribute your testing. You may run an LDTP server and communicate with it via XML-RPC.
The problem with LDTP is that it isn’t well documented. But overall, it looks simple and powerful and I think it’s worth investigating further.
Summary
From a certain perspective end to end functional testing of a complete Evergreen stack is attractive, but a lot of work would have to go into maintaining this regardless of the tools chosen. Our recommendation is that any UI tests focus on the UI itself and not focus heavily on business logic. For example, test that all widgets/controls actually work—that buttons click, checkboxes check, menus open, alerts alert, etc. And also test for non-functional requirements such as performance and scalability. Does the UI leak memory? Is it fast? Can it handle large amounts of data? Exceptions to the no-functional testing bias would include areas where functional behavior was encoded in the UI itself (for example, disabling UI elements based on permission).
New development (particularly any potential replacement staff client) should take testability in mind. For at least one toolkit, this could also include giving consideration to accessibility.
Moving Forward
We recommend that the development community start including integration tests with their changes to the backend, and pgTAP tests with their database changes (there was discussion and general interest in this during a developers meeting).
[http://evergreen-ils.org/meetings/evergreen/2013/evergreen.2013-08-27-14.04.html]
For the existing staff client, the community should invest in a test suite for non-functional aspects of the client, such as speed and memory consumption, to measure improvements and regressions with any attempts to bolster that platform. During the design process for any potential staff client replacement, consideration should be given to how that client might be tested. If a new client will be web-based, the community could apply the same or similar testing strategy to the OPAC.
Appendix A: Survey Results
Overview
Part of the QA project was an attempt to identify the areas of Evergreen that library staff use the most, as well as the areas that staff feel are problematic. With these two pieces of information, the Evergreen developers can best apply QA and other feature development processes to the most critical and the most problematic areas. Consortia and libraries using Evergreen can use the information to drive their own internal testing and development. As described below, the survey results show fairly strong consensus on the usability and the use of Evergreen.
Survey Results
Survey 1: Evergreen Use
This survey was started by 1,086 users and completed by 1,075 users for a retention percentage of 99%. The Circulation section was completed by 971 users. The Cataloging section was completed by 619 users. The Acquisitions section was completed by 395 users. The Admin section was completed by 464 users. The Serials section was completed by 344 users.
The fact that more users filled out the circulation and cataloging sections is unsurprising as that offset reflects the heavier concentration of front-line staff and catalogers in most libraries.
Circulation
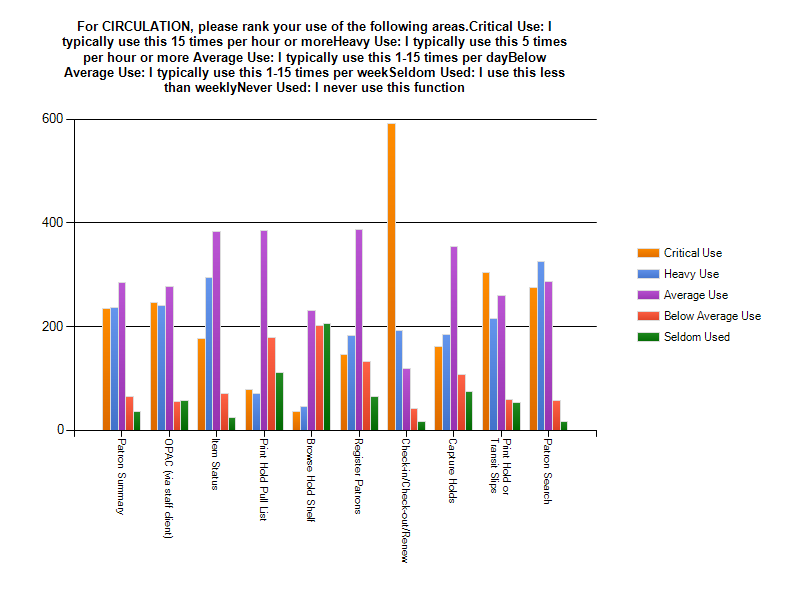
As you can see from the graphed results, users ranked check-in/check-out/renew as the most critical feature for their job. Patron Search and Print Hold/Transit Slips had the next highest use. The feature used the least was Browse Hold Shelf.
Cataloging
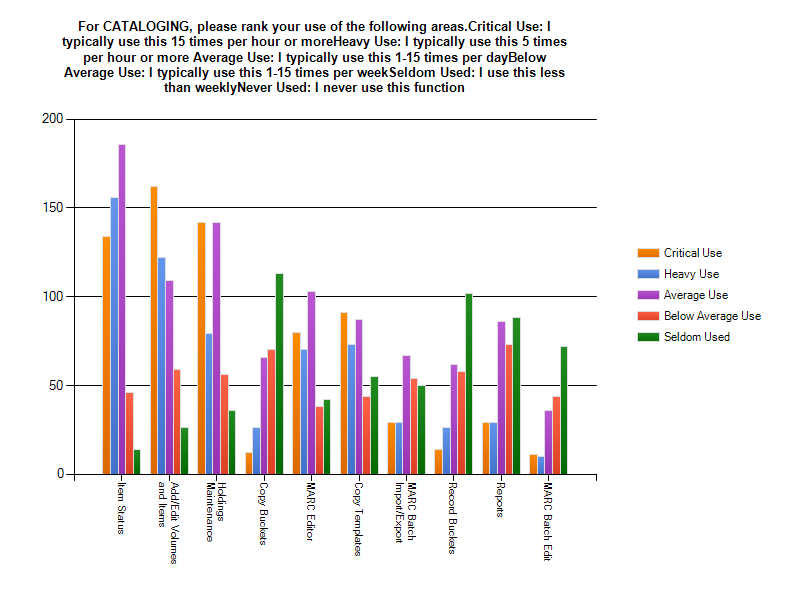
There is a clear indication here that the three most heavily used interfaces are Item Status, Add/Edit MARC Volumes and Items, and Holdings Maintenance. Buckets and Batch Editing are rarely used.
Acquisitions
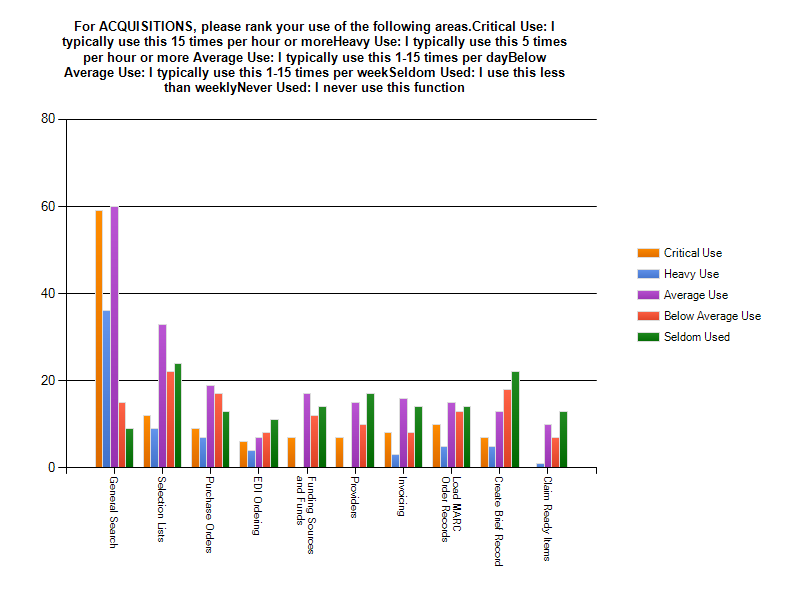
The most heavily used feature in Acquisitions is General Search. This is not surprising since General Search is how you access selection lists, invoices, purchase orders and line item detail in Acquisitions. After General Search, the use in Acquisitions is evenly spread out amongst the rest of the features, with Selection Lists having slightly higher use and Claim Ready Items having the least use.
Admin
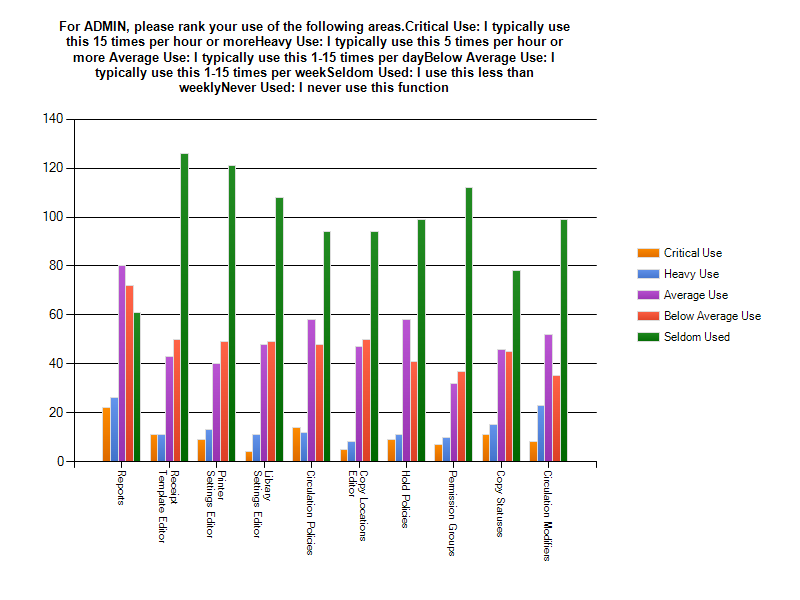
Reports is the most heavily used feature in the Admin category. Circ and Hold Policies, Circulation Modifiers, and Copy Statuses have significant use. It is worth noting here that many respondents left comments that Admin functions are "set it and forget it" and don’t often need updating. While usage of these features isn’t heavy, the features may still be critical.
Serials
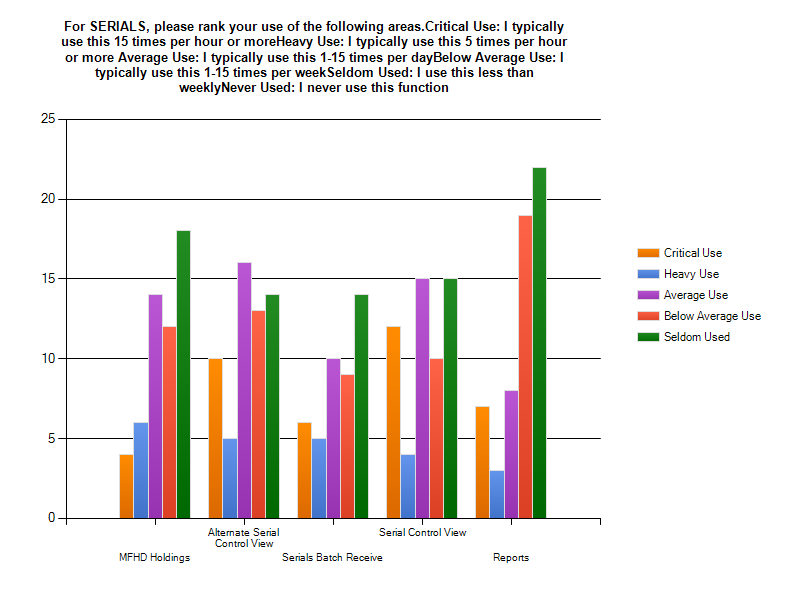
Unsurprisingly, Serials had the fewest responses. The new Serials module is a significant departure from the way Evergreen has handled serial data in the past. Very few institutions are currently using Serials. There isn’t enough data to make a sound judgment on usage of individual interfaces in this category.
Survey 2: Evergreen Usability
This survey was started by 485 users and completed by 482 users for a retention percentage of 99.4%. The Circulation section was completed by 435 users. The Cataloging section was completed by 215 users. The Acquisitions section was completed by 56 users. The Admin section was completed by 108 users. The Serials section was completed by 46 users.
The fact that more users filled out the circulation and cataloging sections is unsurprising as that offset reflects the heavier concentration of front-line staff and catalogers in most libraries.
Circulation
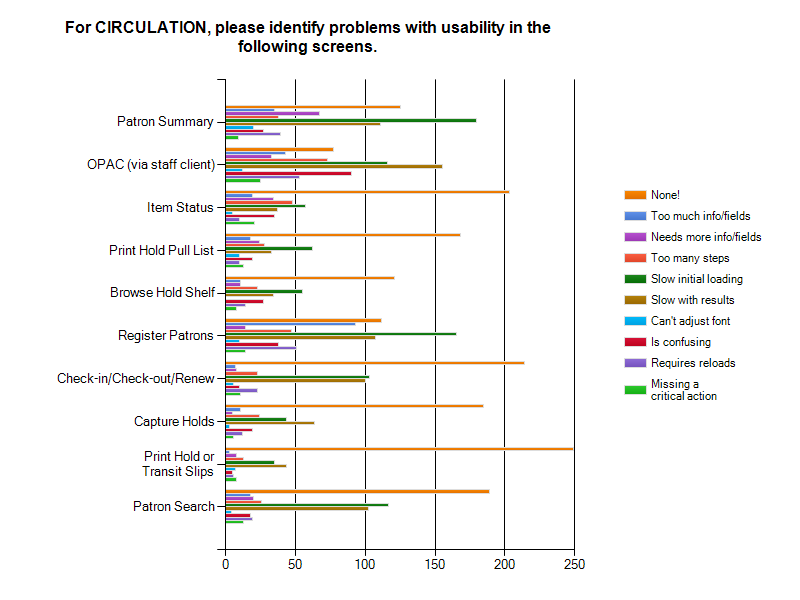
In all but three areas, the end users rated the interfaces as needing no improvement. The OPAC via the staff client was ranked as being slow in initial loading and slow with results. There were some ratings of "confusing" for the OPAC but the comments seem to indicate that those issues may be training, cataloging, or customization related. Patron Summary was also ranked as being slow in initial loading and slow with results. Lastly, respondents indicated that Register Patrons was slow in initial loading and slow with results. A number of people thought that there was too much information or that there were too many fields.
Cataloging
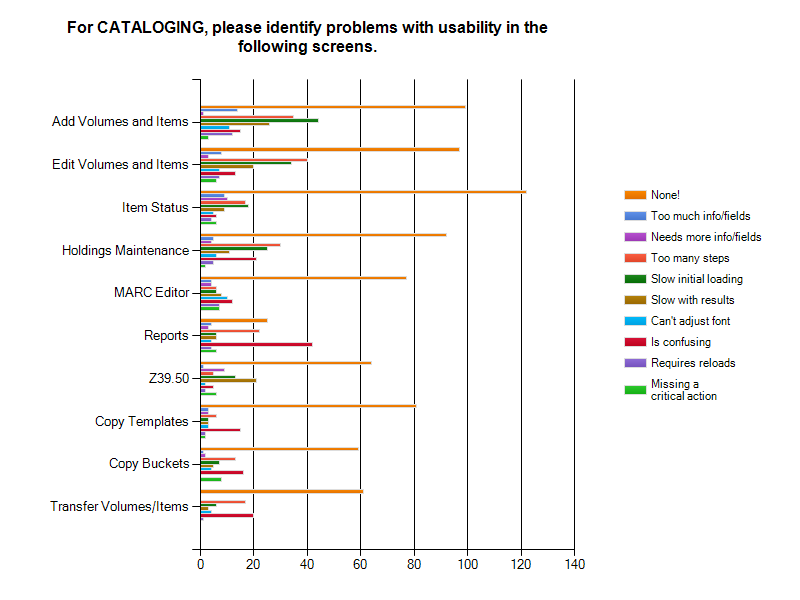
In Cataloging there was only one category that stood out as needing improvement: Reports. Add Volumes and Items, Edit Volumes and Items, and Holdings Maintenance were also marked as slow in initial loading and slow with results.
Acquisitions
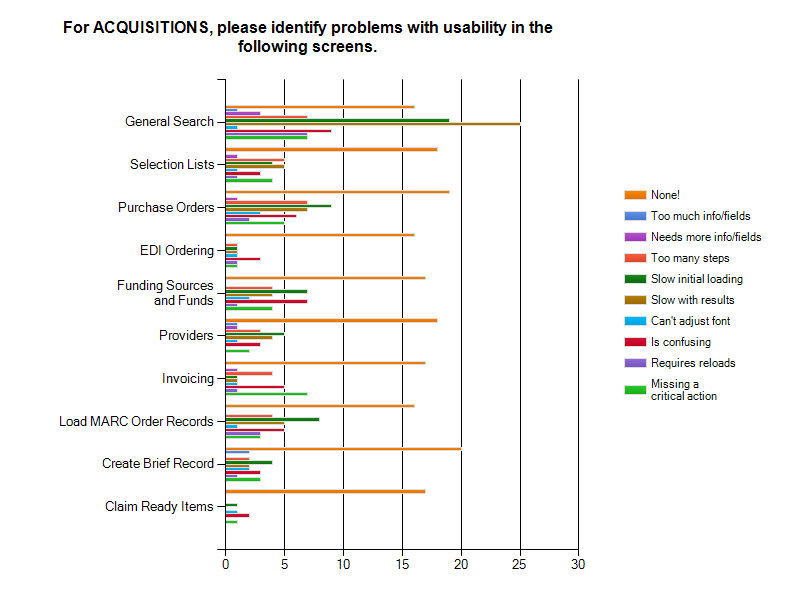
Acquisitions also had good overall ratings with the exception of General Search which was marked as slow in initial loading and slow with results. Notably, Funds and Funding Sources, General Search, and Purchase Orders were all marked as confusing. Since Acquisitions is the newest of Evergreen’s modules, it should likely be the subject of further training and documentation efforts.
Admin
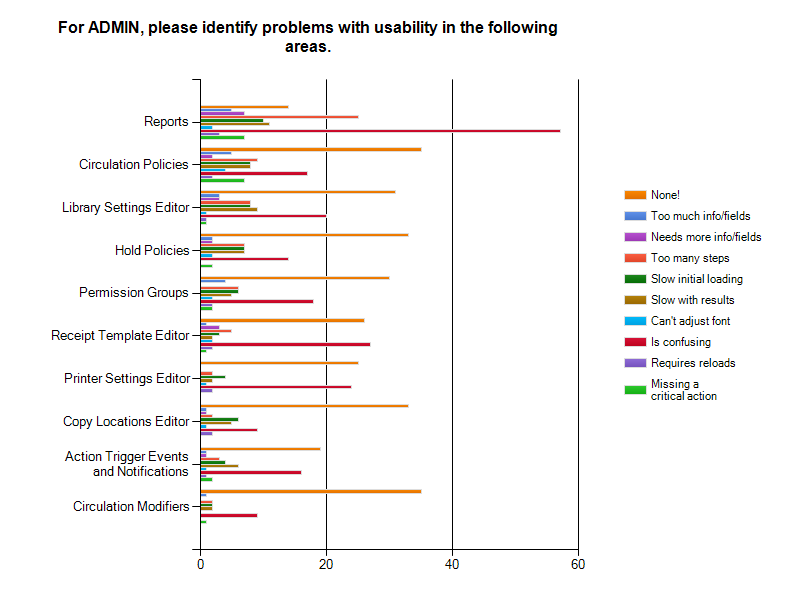
In Admin, Reports were found to be confusing by nearly everyone. In almost every category, the highest response was "None" (meaning no improvement needed) followed by "Is confusing". This outlines nicely the fact that there are people using these more advanced features who aren’t having trouble, but that for many users there is a need for documentation, training, or more clarity in the interfaces.
Serials
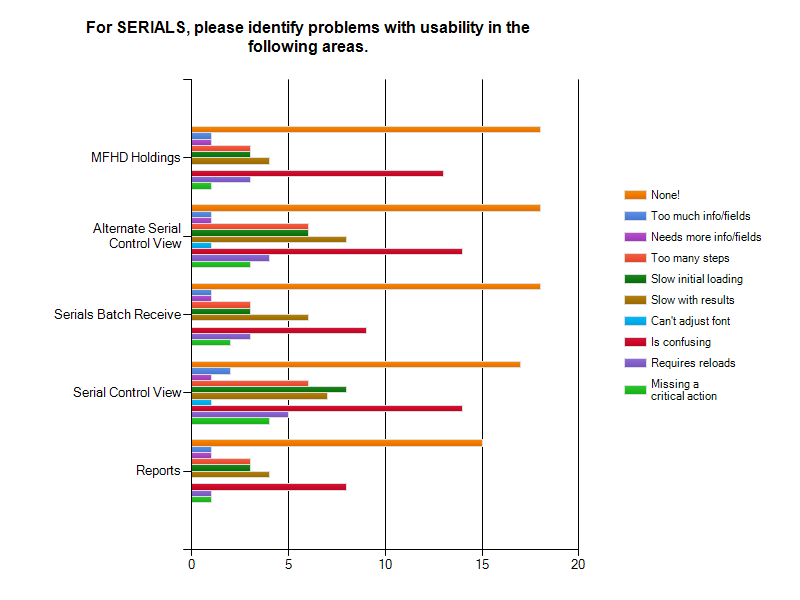
Again, unsurprisingly, serials had the fewest responses. There isn’t enough data to draw strong conclusions, however it is safe to interpret the results as demonstrating the need for documentation, training, or more clarity in the interfaces.
Summary
The data that was collected points toward a general consensus that several Evergreen interfaces are slow to load and slow to render results. A small group also seems to feel that many interfaces (primarily in Serials and Reports) are confusing. There also seems to be a smaller group who believe that there is often too much information on some screens. In the comments, there were several statements regarding the need to click on too many tabs or use too many drop down menus. These comments point to both QA issues as well as development and usability issues that can and should be addressed.
For Circulation, it is important to note that Check-in/Check-out was the most heavily used interface with 61.3% of respondents saying it had critical use and 52.4% of the respondents said it was either slow in loading or rendering. In Cataloging, Add Volumes and Items and Edit Volumes and Items were two of the interfaces with heavy usage and were marked by 40.8% of the respondents as slow in loading and by 39.2% of the respondents as having too many steps. In Acquisitions, the responses indicated that some of the interfaces aren’t clear, in particular Funds and Funding Sources (22.6%). General Search was also noted by 51% of users as slow with results. For Admin, the most reported issue was confusion, particularly for Reports (71.3%). Lastly, Serials respondents reported that the serials screens were confusing with MFHD Holdings being ranked as the most confusing component at 38.2%.
The above summary clearly marks where improvements can be made; however, there may be areas where improvements will be limited until Evergreen moves away from XULRunner. The XULRunner upgrade in Evergreen Release 2.3 did, regrettably and unforeseeably, introduce some memory leaks. These are complicating the relentless developer efforts to improve Evergreen’s speed and stability. There are no quick fixes to the memory leak issues, but the developer community has made the important first step of supporting a move to a browser based staff client that doesn’t depend on XULRunner. There does need to be a second, parallel effort to the new staff client development that will attempt to fix as many issues with the current staff client as possible and continue to create new features for the current staff client. It is not possible to say how long it will take to develop a new staff client, but a reasonable estimate would be between 24 and 48 months, depending on the development path.
I do think that is it important to note here that, with the exception of the Receipt Template Editor, Reports, Register Patrons, Patron Summary, and OPAC via the staff client, the majority of respondents said that there were no improvements to be made to any interface. I think that speaks to the stability and maturity of Evergreen, as well as the strength and aptitude of our community of developers. From the survey and comments, it is clear that despite the recent memory leak issues, Evergreen is still a product that users believe in and like using.
Next Steps
Suggestions moving forward would include ensuring that the most heavily used areas of Evergreen, as indicated by the survey results, receive significant QA treatment when new or changed features are introduced. This isn’t to say that other areas don’t deserve significant QA efforts, but the areas that are of critical use to end-users will cripple their workflow should a bug be introduced. This effort will require adoption of QA guidelines by the core developers as well as stronger effort at testing features and beta releases by the community’s libraries. These efforts will require cooperation, open communication, and time.
The development of a new, browser based staff client is very obviously the next step for Evergreen. The next steps in this direction may include analysis of the findings of the performance assessment that OmniTI is performing for MassLNC. These findings will likely echo known issues (such as XULRunner) but will likely identify issues that are not currently exposed. Another possible step might include a project to create a few prototype staff client interfaces for a browser and then document speed and rendering issues that arise from utilizing the two or three different frameworks that are possible. This project should include the following as metrics: speed, standards compliance, ease of development, widespread support/use of the framework, support for internationalization, QA framework, and any potential challenges of the framework (security, printing, workstation registration, etc.). The sooner that a deliberate method is used to determine which frameworks are going to succeed, the sooner the new staff client can begin development.
Finally, there were many informative comments on the surveys. These comments included complaints, praises, requests for help, and development ideas. Many commenters asked for training on specific features - some even commenting that they weren’t aware a feature existed. This is easily correctable through training and education. In some cases, the users may not be aware of a feature because their consortia’s policy prohibits them from using it. These users should be made aware of the local policies and how those fit into the consortial goals. Those who aren’t prohibited by policy from using a feature should receive ongoing training and be encouraged to go directly to the Evergreen web site to access new feature information and documentation. Some of the complaints were also training issues, for instance not knowing how to configure and save column data. Quality end user training should be a priority in every organization. There also seemed to be a general misunderstanding of the nature of Evergreen and the volunteer nature of all the contributors, including the developers. The three ways to combat this kind of end user misinformation regarding the software itself, as well as the nature of open source, are training, documentation, and communication.